Importing Google Analytics to Neo4j via BigQuery using APOC & JDBC
- July 6, 2018
Google Analytics has been the defacto analytics platform for years. The major problem with this is that Google owns your data and the reporting platform can be difficult to work with.
However, for those with deep pockets and a Google Analytics 360 account, you can link your account with BigQuery and receive automated periodic imports. The BigQuery tables can then be used to import the data into Neo4j, giving you the ability to explore the data using Cypher.
Setting up your Google Project
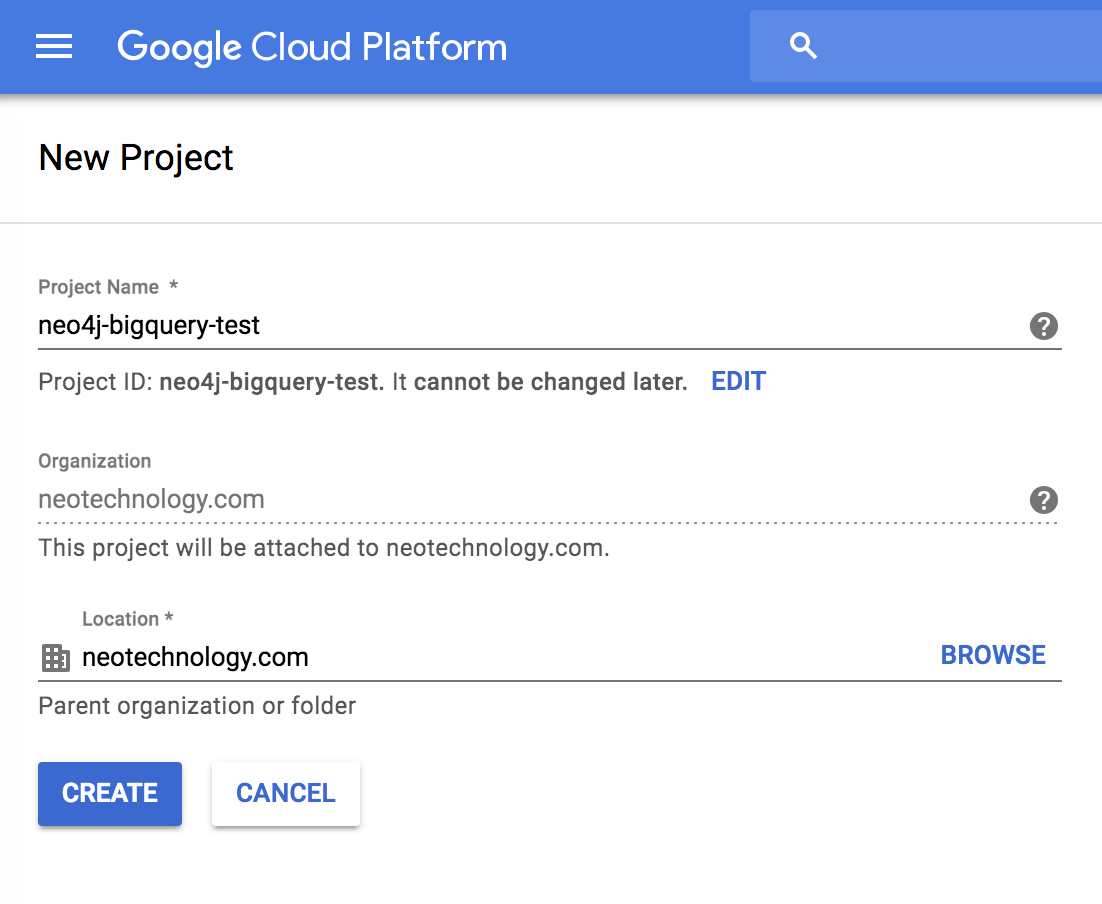
Firstly head over to the Google APIs Console and log in with your Google account. Once you are there, either create a new project or select an existing one. If you are creating a new project, give it a name and click Create.
Next, you’ll need some credentials to connect to BigQuery. You can use OAuth to connect through a google account, but it is by far easier to create a Service Account. On the left hand menu, go to IAM & admin, then Service accounts. At the top of the page you should see a link to Create Service Account.
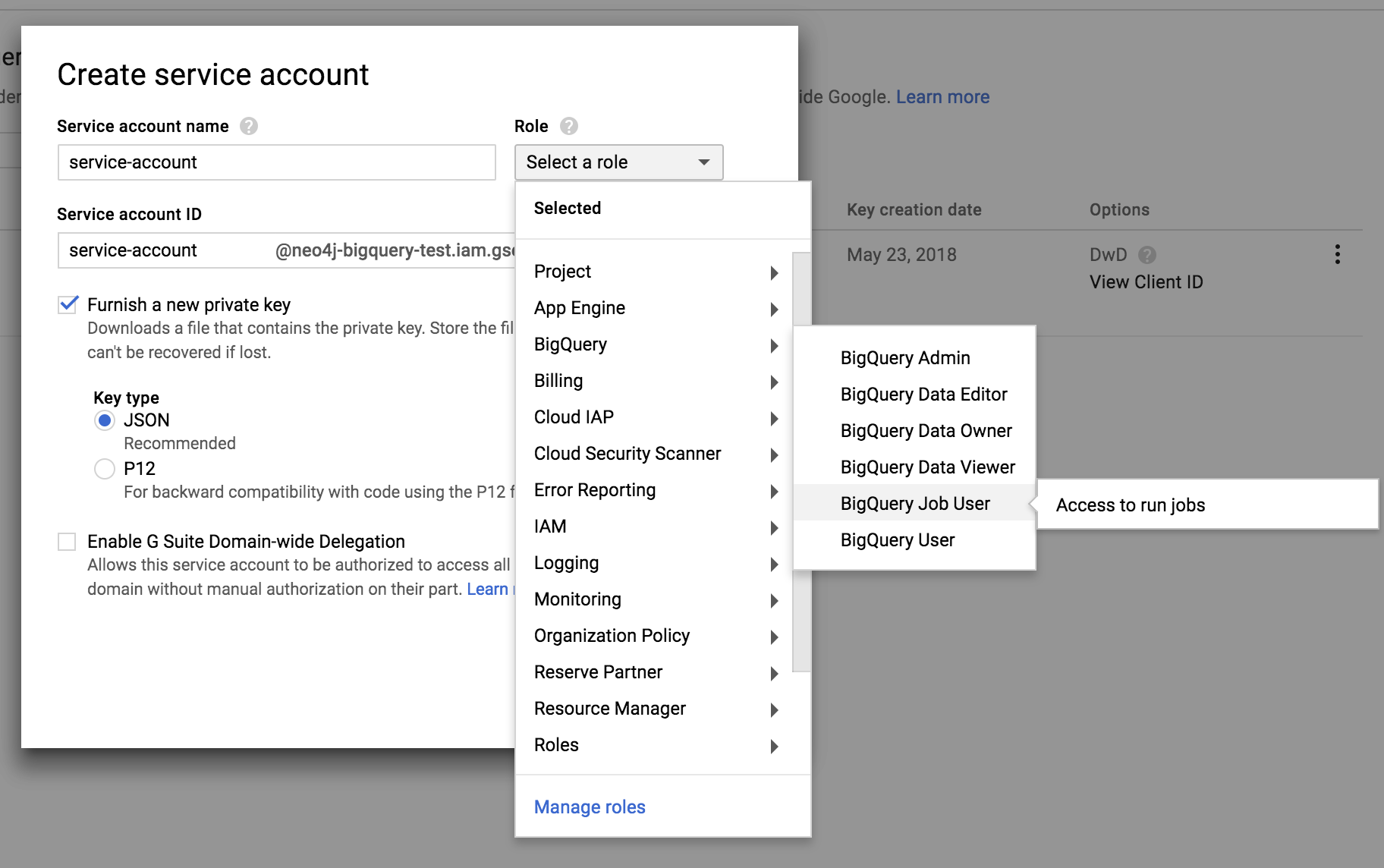
Give the account a name and modify the Service account ID if necessary. The account requires a role of bigquery.jobs.create to run queries, so if you don’t feel comfortable assigning Project > Owner, at the very least set the role to Big Query Data > Big Query Job User. Check the Furnish a new Private Key and select JSON. Once you’ve created the account, make a note of the account ID (*@projectname.iam.gserviceaccount.com) and the location of the downloaded key file (or move it to your $NEO4J_HOME). We’ll need this later on.
Lastly, we’ll be using apoc.load.jdbc to connect to BigQuery. Make sure to add the latest version of APOC and the SIMBA JDBC drivers for BigQuery to your $NEO4J_HOME/plugins folder.
Linking Google Analytics to BigQuery
If you are an OWNER of a property, this can be done with a single click. Under Admin, select the Property that you would like to link to. Then, in the PROPERTY column, click All Products and then Link BigQuery.
The official guide to setting up Google Analytis to BigQuery Export
Exploring the Data Set
So you can follow along, I will be using the sample dataset made available by Google. You can easily switch out the bigquery-public-data project and google_analytics_sample dataset for your own.
The tables are exported daily in the format of ga_sessions_{YYYY}{MM}{DD}. A really nice feature of BigQuery is that you can run queries on multiple tables at once using a wildcard (ga_sessons_201807*) or a where clause (_TABLE_SUFFIX >= '20180701'). But beware, you’re billed by the data that you process during the query. So if you run a query for all tables in a particular year, you could end up with a hefty bill.
If you head to the schema viewer, you’ll see that there is a lot of information available.
BigQuery uses it’s own version of SQL to run queries. Let’s run a query in the console to explore the data.
SELECT
fullVisitorId,
visitorId,
visitNumber,
visitId,
visitStartTime,
date,
hits.time,
hits.page.pagePath,
hits.page.pageTitle,
hits.page.hostname,
trafficSource.campaign,
trafficSource.source,
trafficSource.medium,
trafficSource.keyword,
trafficSource.adwordsClickInfo.campaignId,
geoNetwork.continent,
geoNetwork.subcontinent,
geoNetwork.country,
geoNetwork.region,
geoNetwork.city,
geoNetwork.latitude,
geoNetwork.longitude
FROM [bigquery-public-data:google_analytics_sample.ga_sessions_20170801] LIMIT 1000View an export of the top 1000 rows on Google Sheets
A Note on Unnesting Data
The hits and customDimensions columns inside each ga_sessions_* table are REPEATED fields. Unfortunately, at the moment apoc.load.jdbc does not handle these correctly. These can be unnested into individual rows using the UNNEST function. It means that the cypher query has to do slightly more work but we can get around the issue of multiple duplicates by using MERGE statements instead of CREATE.
As a Graph
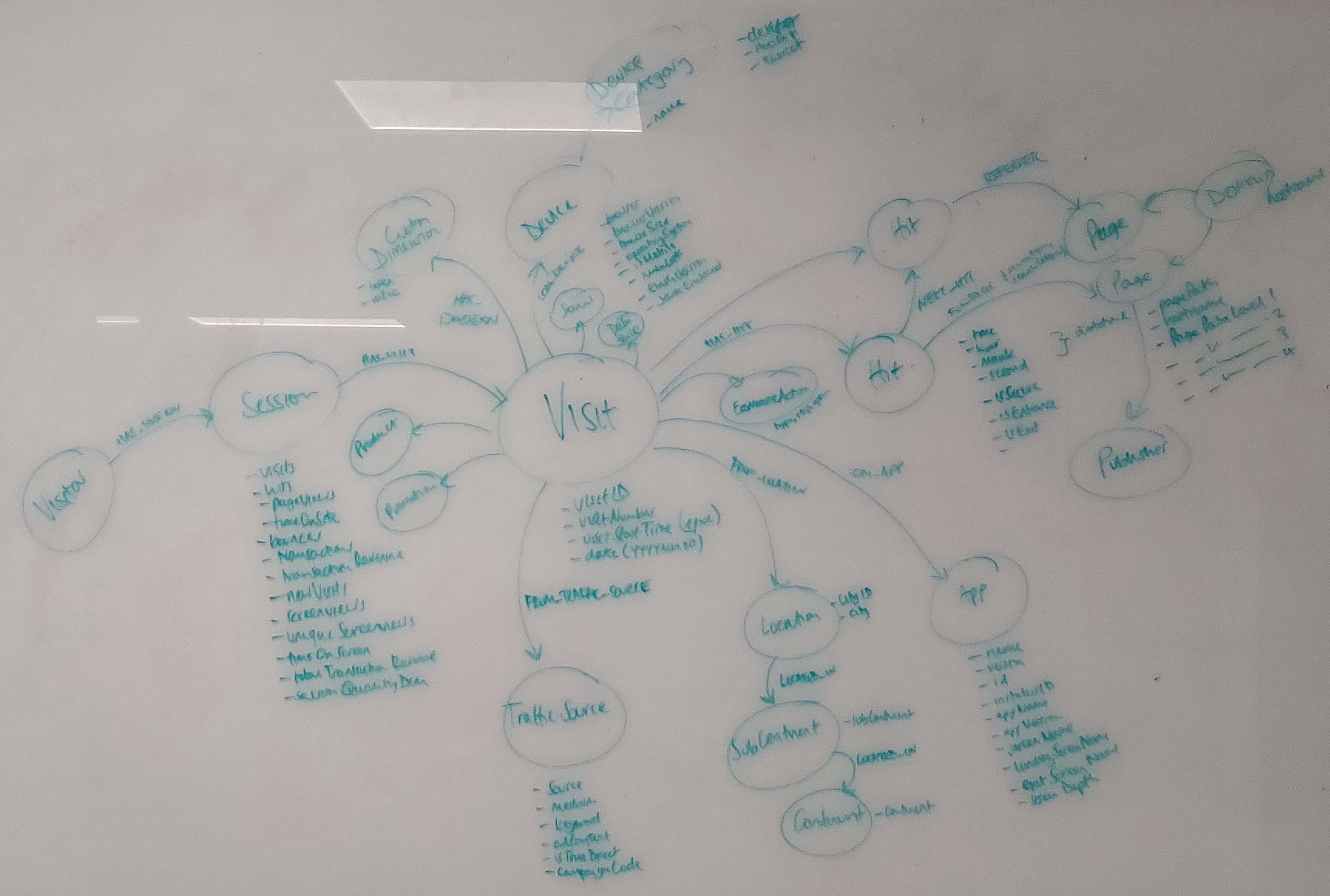
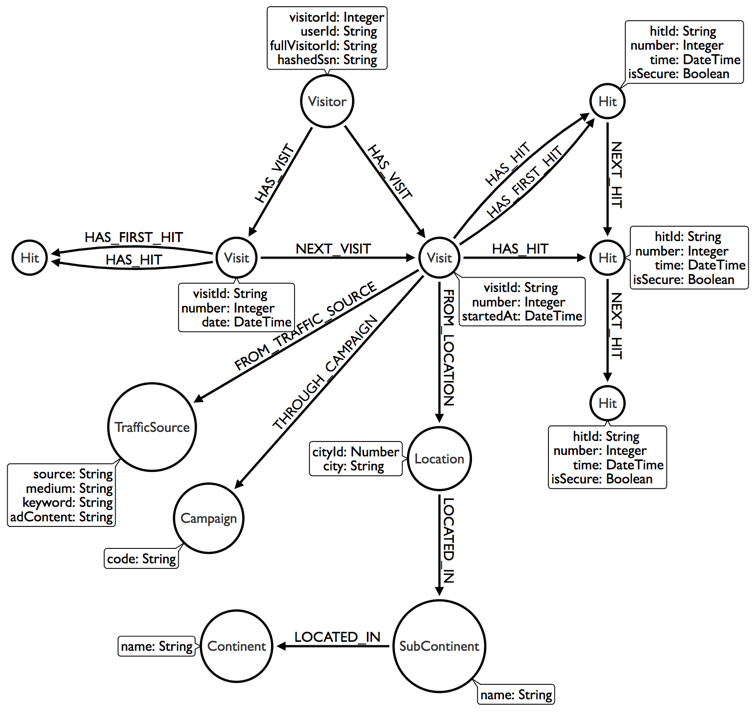
We could represent this in a graph as a set of Visitors, each of which has multiple :Visits which contain one or more :Hits. Each hit (either a pageview or an event) takes place on a :Page which belongs to a :Domain. There is also information on the user’s location, the app that they used. Custom Dimensions and the Traffic Source (source, medium, keywords, adwords content) may also be useful for linking to existing customer records and tracking the success of campaigns. I will stick to a more basic model for now.
Importing to Neo4j using APOC & JDBC
In order to connect to a JDBC source, we need to build up a connection string. APOC includes a apoc.load.jdbc function that yields a stream of rows, each property of which can be accessed through dot or square bracket notation.
CALL apoc.load.jdbc(connectionString, queryOrTable)
YIELD row
RETURN row.propertyThe Connection String
To build a connection string to connect to BigQuery, we’ll need the Service account id and Private key generated above. The JDBC Connection string take a combination of:
jdbc:bigquery://https://www.googleapis.com/bigquery/v2:443;– The JDBC URL for the BigQuery APIProjectId=neo4j-bigquery-test;– The Name of the ProjectOAuthType=0– Instructs the driver to use service-based authentication. You can also use user-based OAuth authentication by setting this to1but this involves popups and copy and pasting urls & keys.OAuthServiceAcctEmail=new-service-account@neo4j-bigquery-test2.iam.gserviceaccount.com– The Service account ID set up earlierOAuthPvtKeyPath=/path/to/neo4j-bigquery-test-327e650dbfe6.json– The path to the key file that downloaded when the credentials were created
The full string should look something like this:
jdbc:bigquery://https://www.googleapis.com/bigquery/v2:443;ProjectId=neo4j-bigquery-test;OAuthType=0;OAuthServiceAcctEmail=neo4j-bigquery-test@neo4j-bigquery-test.iam.gserviceaccount.com;OAuthPvtKeyPath=/path/to/neo4j-bigquery-test-327e650dbfe6.jsonThis connection string is a bit unweildy. When calling apoc.load.jdbc, the procedure will check neo4j.conf file for a corresponding alias under apoc.jdbc.<alias>.url.
# BigQuery Connection String
apoc.jdbc.BigQuery.url=jdbc:bigquery://https://www.googleapis.com/bigquery/v2:443;ProjectId=neo4j-bigquery-test;OAuthType=0;OAuthServiceAcctEmail=neo4j-bigquery-test@neo4j-bigquery-test.iam.gserviceaccount.com;OAuthPvtKeyPath=/path/to/neo4j-bigquery-test-327e650dbfe6.jsonThis makes subsequent calls simpler and protects queries from changes to keys in the future.
CALL apoc.load.jdbc('BigQuery', queryOrTable)
YIELD rowMuch nicer.
The Query
Let’s take the query above and run it through Neo4j with our credentials. When running the query through JDBC, you’ll need to change the format of the table names from [project:dataset.table] to project.dataset.table for example
bigquery-public-data.google_analytics_sample.ga_sessions_20170801.
CALL apoc.load.jdbc('BigQuery', 'SELECT
fullVisitorId,
visitorId,
visitNumber,
visitId,
visitStartTime,
date,
h.time,
h.hitNumber,
h.page.pagePath,
h.page.pageTitle,
h.page.hostname
FROM `bigquery-public-data.google_analytics_sample.ga_sessions_20170801`, UNNEST(hits) AS h')
YIELD row
// ...Now we can use the row to merge the :Visitor, :Visit and :Hit nodes before merging the relationships together.
The start time of the visit is stored as seconds since epoch, so we can store this as a DateTime property introduced in Neo4j 3.4, setting the epochSeconds value in the constructor.
There is no natural key for the hit, so I have combined the visit’s unique ID and the hit number to make a unique key. Where the isInteraction property is free, I have used the foreach hack to set a conditional label to signify that this was an event rather than a pageview.
// ...
YIELD row
MERGE (visitor:Visitor { fullVisitorId: row.fullVisitorId })
SET visitor.visitorId = row.visitorId
MERGE (visit:Visit { visitId: row.visitId })
SET
visit.number = toInteger(row.visitNumber),
visit.startedAt = datetime({ epochSeconds: toInteger(row.visitStartTime) })
MERGE (hit:Hit { hitId: row.visitId + '-'+ row.hitNumber })
SET
hit.number = toInteger(row.hitNumber),
hit.timestamp = datetime({ epochSeconds: toInteger(row.time) })
Foreach Hack to set Interaction label
FOREACH (run IN CASE WHEN hit.isInteraction = 'tru [1] ELSE [] END |
SET hit:Interaction
)
MERGE (host:Host { hostname: tname })
MERGE (page:Page { url: row.hostname + row.pagePath })
ge.hostname = row.hostname, page.path = row.pagePath
MERGE (host)-[:HAS_PAGE]->(page)
MERGE (visitor)-[:HAS_VISIT]->(visit)
(visit)-[:HAS_HIT]->(hit)
MERGE (hit)-[:FOR_PAGE]->(page);Linked Lists
Linked Lists of nodes are useful for a number of situations. Because we have numbers on each hit and visit, we can query, collect and connect them together. This will be useful when analysing user behaviour.
MATCH (visitor:Visitor)-[:HAS_VISIT]->(visit)
// Order visits in ascending order
WITH visitor, visit ORDER BY visit.number ASC
// Collect the visits
isitor, collect(visit) AS visits
// Unwind the ordered collection
range(0, size(visits)-2) AS idx
WITH visits[idx] AS this, visits[idx+1] AS next
MERGE (this)-[:NEXT_VISIT]->(next)I use this technique quite often to create linked lists. First, match the nodes that you are interested in before putting them into the correct order. Next, collect up the nodes – this allows you to calculate the size of the collection and unwind a range of indexes that can be used to create aliases between the two nodes.
With larger datasets, you sometimes need to be a little more cute. Using a :LAST_HIT relationship and identifying new nodes with a temporary label would cut down the number of nodes and relationships touched by the query on a larger dataset.
We can do the same to link up the visits.
MATCH (visit:Visit)-[:HAS_HIT]->(hit)
// Order visits in ascending ord
WITH visit, hit ORDER BY hit.number ASC
// Collect the visits
isit, collect(hit) AS hits
// Unwind the ordered collection
range(0, size(hits)-2) AS idx
WITH hits[idx] AS this, hits[idx+1] AS next
MERGE (this)-[:NEXT_HIT]->(next)Analysis
Now we can start to use the power of the graph to explore the data.
What pages are users visiting?
MATCH (v:Visitor)-[:HAS_VISIT]->()-[:HAS_HIT]->()-[:FOR_PAGE]->(p:Page)
WHERE v.fullVisitorId = {fullVisitorId}
RETURN v.fullVisitorId, p.path, count(*) as visits
ORDER BY visits DESC| v.fullVisitorId | p.path | visits |
|---|---|---|
| “7342454030115611747” | “/store.html” | 151 |
| “7342454030115611747” | “/store.html/quickview” | 147 |
| “7342454030115611747” | “/google+redesign/apparel/mens+tshirts/google+mens+bayside+graphic+tee.axd” | 1 |
| “7342454030115611747” | “/basket.html” | 1 |
| “7342454030115611747” | “/home” | 1 |
| “7342454030115611747” | “/google+redesign/office/stickers/youtube+custom+decals.axd” | 1 |
Next Pages
The :NEXT_HIT relationship allows us to see where a user goes next during their visit.
MATCH (p1:Page)<-[:FOR_PAGE]-()-[:NEXT_HIT]->()-[:FOR_PAGE]->(p2)
WHERE p1 <> p2
RETURN p1.url, p2.url, count(*) as total
ORDER BY total DESC
LIMIT 5| p1.path | p2.path | total |
|---|---|---|
| “/basket.html” | “/yourinfo.html” | 521 |
| “/basket.html” | “/signin.html” | 470 |
| “/yourinfo.html” | “/payment.html” | 451 |
| “/google+redesign/nest/nest-usa” | “/google+redesign/nest/nest-usa/quickview” | 417 |
| “/google+redesign/nest/nest-usa/quickview” | “/google+redesign/nest/nest-usa” | 380 |
Exit Pages
Excluding sessions with a single pageview, where are users exiting the site? By matching a hit where there is both an incoming :NEXT_HIT relationship and no outgoing :NEXT_HIT relationship, we can identify page a user has left the site from.
MATCH (h:Hit)-[:FOR_PAGE]->(p:Page)
WHERE ( ()-[:NEXT_HIT]->(h) ) AND NOT ( (h)-[:NEXT_HIT]->() )
RETURN p.path, count(h) as exists
ORDER BY exists DESC LIMIT 10| p.path | exists |
|---|---|
| “/home” | 588 |
| “/google+redesign/shop+by+brand/youtube” | 195 |
| “/asearch.html” | 163 |
| “/google+redesign/apparel/mens/mens+t+shirts” | 133 |
| “/myaccount.html?mode=vieworderdetail” | 108 |
| “/google+redesign/nest/nest-usa” | 97 |
| “/basket.html” | 97 |
| “/google+redesign/electronics” | 73 |
| “/signin.html” | 58 |
| “/google+redesign/shop+by+brand/youtube/quickview” | 56 |
Conclusion
We’ve just scratched the surface of what is possible when analysing web traffic in Neo4j. With a small amount of extra effort, you can create a sophisticated import script that maps a wealth of information into the graph. Combining this information with existing data sources, for example identifying customers from mailshots using custom dimensions, can lead to a deeper insight into a customer.
Just remember, GDPR…