Turn your CSVs into Graphs using LLMs
- September 27, 2024
As a Friday challenge, I thought I would see how LLMs fare when creating graphs from flat CSV files.
Graph Modelling Fundamentals
The Graph Data Modeling Fundamentals course on GraphAcademy guides you through the basics of modelling data in a graph, but as a first pass I use the following rules of thumb:
- Nouns become labels - they describe the thing that the node represents.
- Verbs become relationship types - they describe how things are connected
- Everything else (particularly Adverbs) becomes a property - you have a name, you may drive a gray car.
Verbs can also be Nodes, you may be happy to know that a person has ordered a product but that basic model doesn’t allow you to know where and when the product was ordered. In this case, Order becomes a new node in the model.
I’m sure this could be distilled into a prompt to create a zero-shot approach to graph data modelling.
An Iterative Approach
I attempted this briefly a few months ago and found that the model I was using became easily distracted when dealing with larger schemas, and the prompts quite quickly reached the LLM’s token limits.
I thought I’d try an iterative approach this time - taking the keys one at a time. This should help avoid distraction because the LLM only needs to consider one item at a time.
The final approach used the following steps:
- Load the CSV file into a Pandas dataframe
- Analyse each column in the CSV and append it to a data model loosely based on JSON Schema
- Identify and add missing unique IDs for each entity
- Review the data model for accuracy
- Generate Cypher statements to import the nodes and relationships
- Generate the unique constraints that underpin the import statements
- Create the constraints and run the import
The Data
I took a quick look on Kaggle for an interesting dataset. The dataset that stood out was Spotify Most Streamed Songs.
import pandas as pd
csv_file = '/Users/adam/projects/datamodeller/data/spotify/spotify-most-streamed-songs.csv'
df = pd.read_csv(csv_file)
df.head()| track_name | artist(s)_name | artist_count | released_year | released_month | released_day | in_spotify_playlists | in_spotify_charts | streams | in_apple_playlists | … | key | mode | danceability_% | valence_% | energy_% | acousticness_% | instrumentalness_% | liveness_% | speechiness_% | cover_url | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | Seven (feat. Latto) (Explicit Ver.) | Latto, Jung Kook | 2 | 2023 | 7 | 14 | 553 | 147 | 141381703 | 43 | … | B | Major | 80 | 89 | 83 | 31 | 0 | 8 | 4 | Not Found |
| 1 | LALA | Myke Towers | 1 | 2023 | 3 | 23 | 1474 | 48 | 133716286 | 48 | … | C# | Major | 71 | 61 | 74 | 7 | 0 | 10 | 4 | https://i.scdn.co/image/ab67616d0000b2730656d5… |
| 2 | vampire | Olivia Rodrigo | 1 | 2023 | 6 | 30 | 1397 | 113 | 140003974 | 94 | … | F | Major | 51 | 32 | 53 | 17 | 0 | 31 | 6 | https://i.scdn.co/image/ab67616d0000b273e85259… |
| 3 | Cruel Summer | Taylor Swift | 1 | 2019 | 8 | 23 | 7858 | 100 | 800840817 | 116 | … | A | Major | 55 | 58 | 72 | 11 | 0 | 11 | 15 | https://i.scdn.co/image/ab67616d0000b273e787cf… |
| 4 | WHERE SHE GOES | Bad Bunny | 1 | 2023 | 5 | 18 | 3133 | 50 | 303236322 | 84 | … | A | Minor | 65 | 23 | 80 | 14 | 63 | 11 | 6 | https://i.scdn.co/image/ab67616d0000b273ab5c9c… |
5 rows × 25 columns
It’s relatively simple, but I can see straight away that there should be relationships between Tracks and Artists.
There are also data cleanliness challenges to overcome, both in terms of column names and artists being comma-separated values within the artist(s)_name column.
Choosing an LLM
I really wanted to use a local LLM for this, but I found out early on that llama3 wouldn’t cut it. If in doubt, fall back to OpenAI.
from langchain_core.prompts import PromptTemplate
from langchain_core.pydantic_v1 import BaseModel, Field
from typing import List
from langchain_core.output_parsers import JsonOutputParser
from langchain_openai import ChatOpenAI
llm = ChatOpenAI(model="gpt-4o")Creating a data model
I used an abridged set of modeling instructions to create the data modeling prompt. I had to engineer the prompt a few times to get a consistent output.
The zero-shot example worked relatively well, but I found that the output was inconsistent. Defining a structured output to hold the JSON output really helped.
JSONSchemaSpecification Class
class JSONSchemaSpecification(BaseModel):
notes: str = Field(description="Any notes or comments about the schema")
jsonschema: str = Field(description="A JSON array of JSON schema specifications that describe the entities in the data model")Few-shot Example Output
The JSON itself was also inconsistent, so I ended up defining a schema based on the movie recommendations dataset.
Example Output
example_output = [
dict(
title="Person",
type="object",
description="Node",
properties=[
dict(name="name", column_name="person_name", type="string", description="The name of the person", examples=["Tom Hanks"]),
dict(name="date_of_birth", column_name="person_dob", type="date", description="The date of birth for the person", examples=["1987-06-05"]),
dict(name="id", column_name="person_name, date_of_birth", type="string", description="The ID is a combination of name and date of birth to ensure uniqueness", examples=["tom-hanks-1987-06-05"]),
],
),
dict(
title="Director",
type="object",
description="Node",
properties=[
dict(name="name", column_name="director_names", type="string", description="The name of the directors. Split values in column by a comma", examples=["Francis Ford Coppola"]),
],
),
dict(
title="Movie",
type="object",
description="Node",
properties=[
dict(name="title", column_name="title", type="string", description="The title of the movie", examples=["Toy Story"]),
dict(name="released", column_name="released", type="integer", description="The year the movie was released", examples=["1990"]),
],
),
dict(
title="ACTED_IN",
type="object",
description="Relationship",
properties=[
dict(name="_from", column_name="od", type="string", description="Person found by the `id`. The ID is a combination of name and date of birth to ensure uniqueness", examples=["Person"]),
dict(name="_to", column_name="title", type="string", description="The movie title", examples=["Movie"]),
dict(name="roles", type="string", column_name="person_roles", description="The roles the person played in the movie", examples=["Woody"]),
],
),
dict(
title="DIRECTED",
type="object",
description="Relationship",
properties=[
dict(name="_from", type="string", column_name="director_names", description="Director names are comma separated", examples=["Director"]),
dict(name="_to", type="string", column_name="title", description="The label of the node this relationship ends at", examples=["Movie"]),
],
),
]I had to deviate from strict JSON schema and add the column_name field to the output to help the LLM generate the import script. Providing examples of descriptions also helped in this regard, otherwise the properties used in the MATCH clause were inconsistent.
The Chain
Here is the final prompt:
model_prompt = PromptTemplate.from_template("""
You are an expert Graph Database administrator.
Your task is to design a data model based on the information provided from an existing data source.
You must decide where the following column fits in with the existing data model. Consider:
* Does the column represent an entity, for example a Person, Place, or Movie? If so, this should be a node in its own right.
* Does the column represent a relationship between two entities? If so, this should be a relationship between two nodes.
* Does the column represent an attribute of an entity or relationship? If so, this should be a property of a node or relationship.
* Does the column represent a shared attribute that could be interesting to query through to find similar nodes, for example a Genre? If so, this should be a node in its own right.
## Instructions for Nodes
* Node labels are generally nouns, for example Person, Place, or Movie
* Node titles should be in UpperCamelCase
## Instructions for Relationships
* Relationshops are generally verbs, for example ACTED_IN, DIRECTED, or PURCHASED
* Examples of good relationships are (:Person)-[:ACTED_IN]->(:Movie) or (:Person)-[:PURCHASED]->(:Product)
* Relationships should be in UPPER_SNAKE_CASE
* Provide any specific instructions for the field in the description. For example, does the field contain a list of comma separated values or a single value?
## Instructions for Properties
* Relationships should be in lowerPascalCase
* Prefer the shorter name where possible, for example "person_id" and "personId" should simply be "id"
* If you are changing the property name from the original field name, mention the column name in the description
* Do not include examples for integer or date fields
* Always include instructions on data preparation for the field. Does it need to be cast as a string or split into multiple fields on a delimiting value?
* Property keys should be letters only, no numbers or special characters.
## Important!
Consider the examples provided. Does any data preparation need to be done to ensure the data is in the correct format?
You must include any information about data preparation in the description.
## Example Output
Here is an example of a good output:
```
{example_output}
```
## New Data:
Key: {key}
Data Type: {type}
Example Values: {examples}
## Existing Data Model
Here is the existing data model:
```
{existing_model}
```
## Keep Existing Data Model
Apply your changes to the existing data model but never remove any existing definitions.
""", partial_variables=dict(example_output=dumps(example_output)))
model_chain = model_prompt | llm.with_structured_output(JSONSchemaSpecification)Executing the Chain
To iteratively update the model, I iterated over the keys in the dataframe and passed each key, its datatype and the first five unique values to the prompt.
from json_repair import dumps, loads
existing_model = {}
for i, key in enumerate(df):
print("\n", i, key)
print("----------------")
try:
res = try_chain(model_chain, dict(
existing_model=dumps(existing_model),
key=key,
type=df[key].dtype,
examples=dumps(df[key].unique()[:5].tolist())
))
print(res.notes)
existing_model = loads(res.jsonschema)
print([n['title'] for n in existing_model])
except Exception as e:
print(e)
pass
existing_modelConsole Output
0 track_name
----------------
Adding 'track_name' to an existing data model. This represents a music track entity.
['Track']
1 artist(s)_name
----------------
Adding a new column 'artist(s)_name' to the existing data model. This column represents multiple artists associated with tracks and should be modeled as a new node 'Artist' and a relationship 'PERFORMED_BY' from 'Track' to 'Artist'.
['Track', 'Artist', 'PERFORMED_BY']
2 artist_count
----------------
Added artist_count as a property of Track node. This property indicates the number of artists performing in the track.
['Track', 'Artist', 'PERFORMED_BY']
3 released_year
----------------
Add the released_year column to the existing data model as a property of the Track node.
['Track', 'Artist', 'PERFORMED_BY']
4 released_month
----------------
Adding the 'released_month' column to the existing data model, considering it as an attribute of the Track node.
['Track', 'Artist', 'PERFORMED_BY']
5 released_day
----------------
Added a new property 'released_day' to the 'Track' node to capture the day of the month a track was released.
['Track', 'Artist', 'PERFORMED_BY']
6 in_spotify_playlists
----------------
Adding the new column 'in_spotify_playlists' to the existing data model as a property of the 'Track' node.
['Track', 'Artist', 'PERFORMED_BY']
7 in_spotify_charts
----------------
Adding the 'in_spotify_charts' column to the existing data model as a property of the Track node.
['Track', 'Artist', 'PERFORMED_BY']
8 streams
----------------
Adding a new column 'streams' to the existing data model, representing the number of streams for a track.
['Track', 'Artist', 'PERFORMED_BY']
9 in_apple_playlists
----------------
Adding new column 'in_apple_playlists' to the existing data model
['Track', 'Artist', 'PERFORMED_BY']
10 in_apple_charts
----------------
Adding 'in_apple_charts' as a property to the 'Track' node, representing the number of times the track appeared in the Apple charts.
['Track', 'Artist', 'PERFORMED_BY']
11 in_deezer_playlists
----------------
Add 'in_deezer_playlists' to the existing data model for a music track database.
['Track', 'Artist', 'PERFORMED_BY']
12 in_deezer_charts
----------------
Adding a new property 'inDeezerCharts' to the existing 'Track' node to represent the number of times the track appeared in Deezer charts.
['Track', 'Artist', 'PERFORMED_BY']
13 in_shazam_charts
----------------
Adding new data 'in_shazam_charts' to the existing data model. This appears to be an attribute of the 'Track' node, indicating the number of times a track appeared in the Shazam charts.
['Track', 'Artist', 'PERFORMED_BY']
14 bpm
----------------
Added bpm column as a property to the Track node as it represents a characteristic of the track.
['Track', 'Artist', 'PERFORMED_BY']
15 key
----------------
Adding the 'key' column to the existing data model. The 'key' represents the musical key of a track, which is a shared attribute that can be interesting to query through to find similar tracks.
['Track', 'Artist', 'PERFORMED_BY']
16 mode
----------------
Adding 'mode' to the existing data model. It represents a musical characteristic of a track, which is best captured as an attribute of the Track node.
['Track', 'Artist', 'PERFORMED_BY']
17 danceability_%
----------------
Added 'danceability_%' to the existing data model as a property of the Track node. The field represents the danceability percentage of the track.
['Track', 'Artist', 'PERFORMED_BY']
18 valence_%
----------------
Adding the valence percentage column to the existing data model as a property of the Track node.
['Track', 'Artist', 'PERFORMED_BY']
19 energy_%
----------------
Integration of the new column 'energy_%' into the existing data model. This column represents an attribute of the Track entity and should be added as a property of the Track node.
['Track', 'Artist', 'PERFORMED_BY']
20 acousticness_%
----------------
Adding acousticness_% to the existing data model as a property of the Track node.
['Track', 'Artist', 'PERFORMED_BY']
21 instrumentalness_%
----------------
Adding the new column 'instrumentalness_%' to the existing Track node as it represents an attribute of the Track entity.
['Track', 'Artist', 'PERFORMED_BY']
22 liveness_%
----------------
Adding the new column 'liveness_%' to the existing data model as an attribute of the Track node
['Track', 'Artist', 'PERFORMED_BY']
23 speechiness_%
----------------
Adding the new column 'speechiness_%' to the existing data model as a property of the 'Track' node.
['Track', 'Artist', 'PERFORMED_BY']
24 cover_url
----------------
Adding a new property 'cover_url' to the existing 'Track' node. This property represents the URL of the track's cover image.
['Track', 'Artist', 'PERFORMED_BY']After a few tweaks to the prompt to handle use cases, I ended up with a model I was quite happy with. The LLM had managed to determine that the dataset consisted of Tracks, Artists and a
PERFORMED_BY relationship to connect the two together.
[
{
"title": "Track",
"type": "object",
"description": "Node",
"properties": [
{
"name": "name",
"column_name": "track_name",
"type": "string",
"description": "The name of the track",
"examples": [
"Seven (feat. Latto) (Explicit Ver.)",
"LALA",
"vampire",
"Cruel Summer",
"WHERE SHE GOES",
],
},
{
"name": "artist_count",
"column_name": "artist_count",
"type": "integer",
"description": "The number of artists performing in the track",
"examples": [2, 1, 3, 8, 4],
},
{
"name": "released_year",
"column_name": "released_year",
"type": "integer",
"description": "The year the track was released",
"examples": [2023, 2019, 2022, 2013, 2014],
},
{
"name": "released_month",
"column_name": "released_month",
"type": "integer",
"description": "The month the track was released",
"examples": [7, 3, 6, 8, 5],
},
{
"name": "released_day",
"column_name": "released_day",
"type": "integer",
"description": "The day of the month the track was released",
"examples": [14, 23, 30, 18, 1],
},
{
"name": "inSpotifyPlaylists",
"column_name": "in_spotify_playlists",
"type": "integer",
"description": "The number of Spotify playlists the track is in. Cast the value as an integer.",
"examples": [553, 1474, 1397, 7858, 3133],
},
{
"name": "inSpotifyCharts",
"column_name": "in_spotify_charts",
"type": "integer",
"description": "The number of times the track appeared in the Spotify charts. Cast the value as an integer.",
"examples": [147, 48, 113, 100, 50],
},
{
"name": "streams",
"column_name": "streams",
"type": "array",
"description": "The list of stream IDs for the track. Maintain the array format.",
"examples": [
"141381703",
"133716286",
"140003974",
"800840817",
"303236322",
],
},
{
"name": "inApplePlaylists",
"column_name": "in_apple_playlists",
"type": "integer",
"description": "The number of Apple playlists the track is in. Cast the value as an integer.",
"examples": [43, 48, 94, 116, 84],
},
{
"name": "inAppleCharts",
"column_name": "in_apple_charts",
"type": "integer",
"description": "The number of times the track appeared in the Apple charts. Cast the value as an integer.",
"examples": [263, 126, 207, 133, 213],
},
{
"name": "inDeezerPlaylists",
"column_name": "in_deezer_playlists",
"type": "array",
"description": "The list of Deezer playlist IDs the track is in. Maintain the array format.",
"examples": ["45", "58", "91", "125", "87"],
},
{
"name": "inDeezerCharts",
"column_name": "in_deezer_charts",
"type": "integer",
"description": "The number of times the track appeared in the Deezer charts. Cast the value as an integer.",
"examples": [10, 14, 12, 15, 17],
},
{
"name": "inShazamCharts",
"column_name": "in_shazam_charts",
"type": "array",
"description": "The list of Shazam chart IDs the track is in. Maintain the array format.",
"examples": ["826", "382", "949", "548", "425"],
},
{
"name": "bpm",
"column_name": "bpm",
"type": "integer",
"description": "The beats per minute of the track. Cast the value as an integer.",
"examples": [125, 92, 138, 170, 144],
},
{
"name": "key",
"column_name": "key",
"type": "string",
"description": "The musical key of the track. Cast the value as a string.",
"examples": ["B", "C#", "F", "A", "D"],
},
{
"name": "mode",
"column_name": "mode",
"type": "string",
"description": "The mode of the track (e.g., Major, Minor). Cast the value as a string.",
"examples": ["Major", "Minor"],
},
{
"name": "danceability",
"column_name": "danceability_%",
"type": "integer",
"description": "The danceability percentage of the track. Cast the value as an integer.",
"examples": [80, 71, 51, 55, 65],
},
{
"name": "valence",
"column_name": "valence_%",
"type": "integer",
"description": "The valence percentage of the track. Cast the value as an integer.",
"examples": [89, 61, 32, 58, 23],
},
{
"name": "energy",
"column_name": "energy_%",
"type": "integer",
"description": "The energy percentage of the track. Cast the value as an integer.",
"examples": [83, 74, 53, 72, 80],
},
{
"name": "acousticness",
"column_name": "acousticness_%",
"type": "integer",
"description": "The acousticness percentage of the track. Cast the value as an integer.",
"examples": [31, 7, 17, 11, 14],
},
{
"name": "instrumentalness",
"column_name": "instrumentalness_%",
"type": "integer",
"description": "The instrumentalness percentage of the track. Cast the value as an integer.",
"examples": [0, 63, 17, 2, 19],
},
{
"name": "liveness",
"column_name": "liveness_%",
"type": "integer",
"description": "The liveness percentage of the track. Cast the value as an integer.",
"examples": [8, 10, 31, 11, 28],
},
{
"name": "speechiness",
"column_name": "speechiness_%",
"type": "integer",
"description": "The speechiness percentage of the track. Cast the value as an integer.",
"examples": [4, 6, 15, 24, 3],
},
{
"name": "coverUrl",
"column_name": "cover_url",
"type": "string",
"description": "The URL of the track's cover image. If the value is 'Not Found', it should be cast as an empty string.",
"examples": [
"https://i.scdn.co/image/ab67616d0000b2730656d5ce813ca3cc4b677e05",
"https://i.scdn.co/image/ab67616d0000b273e85259a1cae29a8d91f2093d",
],
},
],
},
{
"title": "Artist",
"type": "object",
"description": "Node",
"properties": [
{
"name": "name",
"column_name": "artist(s)_name",
"type": "string",
"description": "The name of the artist. Split values in column by a comma",
"examples": [
"Latto",
"Jung Kook",
"Myke Towers",
"Olivia Rodrigo",
"Taylor Swift",
"Bad Bunny",
],
}
],
},
{
"title": "PERFORMED_BY",
"type": "object",
"description": "Relationship",
"properties": [
{
"name": "_from",
"type": "string",
"description": "The label of the node this relationship starts at",
"examples": ["Track"],
},
{
"name": "_to",
"type": "string",
"description": "The label of the node this relationship ends at",
"examples": ["Artist"],
},
],
},
]Adding Unique Identifiers
I noticed that the schema didn’t contain any unique identifiers and this may become a problem when it comes to importing relationships. It stands to reason that different artists would release songs with the same name and two artists may have the same name.
For this reason, it was important to create an identifier for Tracks so they could be differentiated within a larger dataset.
# Add primary key/unique identifiers
uid_prompt = PromptTemplate.from_template("""
You are a graph database expert reviewing a single entity from a data model generated by a colleague.
You want to ensure that all of the nodes imported into the database are unique.
## Example
A schema contains Actors with a number of properties including name, date of birth.
Two actors may have the same name then add a new compound property combining the name and date of birth.
If combining values, include the instruction to convert the value to slug case. Call the new property 'id'.
If you have identified a new property, add it to the list of properties leaving the rest intact.
Include in the description the fields that are to be concatenated.
## Example Output
Here is an example of a good output:
```
{example_output}
```
## Current Entity Schema
```
{entity}
```
""", partial_variables=dict(example_output=dumps(example_output)))
uid_chain = uid_prompt | llm.with_structured_output(JSONSchemaSpecification)This step is only really required for nodes, so I extracted the nodes from the schema, ran the chain for each and then combined the relationships with the updated definitions.
# extract nodes and relationships
nodes = [n for n in existing_model if "node" in n["description"].lower()]
rels = [n for n in existing_model if "node" not in n["description"].lower()]
# generate a unique id for nodes
with_uids = []
for entity in nodes:
res = uid_chain.invoke(dict(entity=dumps(entity)))
json = loads(res.jsonschema)
with_uids = with_uids + json if type(json) == list else with_uids + [json]
# combine nodes and relationships
with_uids = with_uids + relsData Model Review
For sanity, it is worth checking the model for optimisations. The model_prompt did a good job of identifying the nouns and verbs, but in a more complex model.
One iteration treated the *_playlists and _charts columns as IDs and attempted to create Stream nodes and IN_PLAYLIST relationships. I assume due to the counts over 1000 including formating with a comma (eg. 1,001).
Nice idea, maybe a little too clever. But this shows the importance of having a human in the loop that understands the data structure.
Reveal full prompt
# Add primary key/unique identifiers
review_prompt = PromptTemplate.from_template("""
You are a graph database expert reviewing a data model generated by a colleague.
Your task is to review the data model and ensure that it is fit for purpose.
Check for:
## Check for nested objects
Remember that Neo4j cannot store arrays of objects or nested objects.
These must be converted into into separate nodes with relationships between them.
You must include the new node and a reference to the relationship to the output schema.
## Check for Entities in properties
If there is a property that represents an array of IDs, a new node should be created for that entity.
You must include the new node and a reference to the relationship to the output schema.
# Keep Instructions
Ensure that the instructions for the nodes, relationships, and properties are clear and concise.
You may improve them but the detail must not be removed in any circumstances.
## Current Entity Schema
```
{entity}
```
""")
review_chain = review_prompt | llm.with_structured_output(JSONSchemaSpecification)
review_nodes = [n for n in with_uids if "node" in n["description"].lower() ]
review_rels = [n for n in with_uids if "node" not in n["description"].lower() ]
reviewed = []
for entity in review_nodes:
res = review_chain.invoke(dict(entity=dumps(entity)))
json = loads(res.jsonschema)
reviewed = reviewed + json
# add relationships back in
reviewed = reviewed + review_rels
len(reviewed)
reviewed = with_uidsIn a real-world scenario, I’d want to run this a few times to iteratively improve the data model. I would put a maximum limit, and then iterate up to that point or the data model object no longer changes.
Generate Import Statements
By this point, the schema should be robust enough and include as much information as possible to allow an LLM to generate a set of import scripts.
In line with Neo4j data importing recommendations, the file should be processed several times, each time importing a single node or relationship to avoid eager operations and locking.
import_prompt = PromptTemplate.from_template("""
Based on the data model, write a Cypher statement to import the following data from a CSV file into Neo4j.
Do not use LOAD CSV as this data will be imported using the Neo4j Python Driver, use UNWIND on the $rows parameter instead.
You are writing a multi-pass import process, so concentrate on the entity mentioned.
When importing data, you must use the following guidelines:
* follow the instructions in the description when identifying primary keys.
* Use the instructions in the description to determine the format of properties when a finding.
* When combining fields into an ID, use the apoc.text.slug function to convert any text to slug case and toLower to convert the string to lowercase - apoc.text.slug(toLower(row.`name`))
* If you split a property, convert it to a string and use the trim function to remove any whitespace - trim(toString(row.`name`))
* When combining properties, wrap each property in the coalesce function so the property is not null if one of the values is not set - coalesce(row.`id`, '') + '--'+ coalsece(row.`title`)
* Use the `column_name` field to map the CSV column to the property in the data model.
* Wrap all column names from the CSV in backticks - for example row.`column_name`.
* When you merge nodes, merge on the unique identifier and nothing else. All other properties should be set using `SET`.
* Do not use apoc.periodic.iterate, the files will be batched in the application.
Data Model:
```
{data_model}
```
Current Entity:
```
{entity}
```
""")This chain requires a different output object to the previous steps. In this case, the cypher member is most important, but I also wanted to include a chain_of_thought key to encourage Chain of Thought.
class CypherOutputSpecification(BaseModel):
chain_of_thought: str = Field(description="Any reasoning used to write the Cypher statement")
cypher: str = Field(description="The Cypher statement to import the data")
notes: Optional[str] = Field(description="Any notes or closing remarks about the Cypher statement")
import_chain = import_prompt | llm.with_structured_output(CypherOutputSpecification)The same process then applies to iterate over each of the reviewed definitions and generate the Cypher.
import_cypher = []
for n in reviewed:
print('\n\n------', n['title'])
res = import_chain.invoke(dict(
data_model=dumps(reviewed),
entity=n
))
import_cypher.append((
res.cypher
))
print(res.cypher)
Console Output
------ Track
UNWIND $rows AS row
MERGE (t:Track {id: apoc.text.slug(toLower(coalesce(row.`track_name`, '') + '-' + coalesce(row.`released_year`, '')))})
SET t.name = trim(toString(row.`track_name`)),
t.artist_count = toInteger(row.`artist_count`),
t.released_year = toInteger(row.`released_year`),
t.released_month = toInteger(row.`released_month`),
t.released_day = toInteger(row.`released_day`),
t.inSpotifyPlaylists = toInteger(row.`in_spotify_playlists`),
t.inSpotifyCharts = toInteger(row.`in_spotify_charts`),
t.streams = row.`streams`,
t.inApplePlaylists = toInteger(row.`in_apple_playlists`),
t.inAppleCharts = toInteger(row.`in_apple_charts`),
t.inDeezerPlaylists = row.`in_deezer_playlists`,
t.inDeezerCharts = toInteger(row.`in_deezer_charts`),
t.inShazamCharts = row.`in_shazam_charts`,
t.bpm = toInteger(row.`bpm`),
t.key = trim(toString(row.`key`)),
t.mode = trim(toString(row.`mode`)),
t.danceability = toInteger(row.`danceability_%`),
t.valence = toInteger(row.`valence_%`),
t.energy = toInteger(row.`energy_%`),
t.acousticness = toInteger(row.`acousticness_%`),
t.instrumentalness = toInteger(row.`instrumentalness_%`),
t.liveness = toInteger(row.`liveness_%`),
t.speechiness = toInteger(row.`speechiness_%`),
t.coverUrl = CASE row.`cover_url` WHEN 'Not Found' THEN '' ELSE trim(toString(row.`cover_url`)) END
------ Artist
UNWIND $rows AS row
WITH row, split(row.`artist(s)_name`, ',') AS artistNames
UNWIND artistNames AS artistName
MERGE (a:Artist {id: apoc.text.slug(toLower(trim(artistName)))})
SET a.name = trim(artistName)
------ PERFORMED_BY
UNWIND $rows AS row
UNWIND split(row.`artist(s)_name`, ',') AS artist_name
MERGE (t:Track {id: apoc.text.slug(toLower(row.`track_name`)) + '-' + trim(toString(row.`released_year`))})
MERGE (a:Artist {id: apoc.text.slug(toLower(trim(artist_name)))})
MERGE (t)-[:PERFORMED_BY]->(a)
This prompt took some engineering to achieve consistent results.
- Sometimes the Cypher would include
MERGEstatement with multiple fields defined, which is sub-optimal at best. If any of the columns arenull, the entire import will fail. - At times the result would include
apoc.period.iterate, which is no longer required, and furthermore I wanted code that I could execute with the Python driver. - I had to reiterate that the specified column name should be used when creating relationships.
- The LLM just wouldn’t follow the instructions when using the unique identifier on the nodes at each end of the relationship, so this took a few attempts to get it to follow the instructions in the description. There was some back-and-forth between this prompt and the
model_prompt. - Backticks were needed for the column names that included special characters (eg.
energy_%)
It would also be beneficial to split this into two prompts, one for nodes and one for relationships. But that is a task for another day.
Create the Unique Constraints
Next, the import scripts can be used as a basis to create unique constraints in the database.
constraint_prompt = PromptTemplate.from_template("""
You are an expert graph database administrator.
Use the following Cypher statement to write a Cypher statement to
create unique constraints on any properties used in a MERGE statement.
The correct syntax for a unique constraint is:
CREATE CONSTRAINT movie_title_id IF NOT EXISTS FOR (m:Movie) REQUIRE m.title IS UNIQUE;
Cypher:
```
{cypher}
```
""")
constraint_chain = constraint_prompt | llm.with_structured_output(CypherOutputSpecification)
constraint_queries = []
for statement in import_cypher:
res = constraint_chain.invoke(dict(cypher=statement))
statements = res.cypher.split(";")
for cypher in statements:
constraint_queries.append(cypher)Console Output
CREATE CONSTRAINT track_id_unique IF NOT EXISTS FOR (t:Track) REQUIRE t.id IS UNIQUE
CREATE CONSTRAINT stream_id IF NOT EXISTS FOR (s:Stream) REQUIRE s.id IS UNIQUE
CREATE CONSTRAINT playlist_id IF NOT EXISTS FOR (p:Playlist) REQUIRE p.id IS UNIQUE
CREATE CONSTRAINT chart_id IF NOT EXISTS FOR (c:Chart) REQUIRE c.id IS UNIQUE
CREATE CONSTRAINT track_id_unique IF NOT EXISTS FOR (t:Track) REQUIRE t.id IS UNIQUE
CREATE CONSTRAINT stream_id_unique IF NOT EXISTS FOR (s:Stream) REQUIRE s.id IS UNIQUE
CREATE CONSTRAINT track_id_unique IF NOT EXISTS FOR (t:Track) REQUIRE t.id IS UNIQUE
CREATE CONSTRAINT playlist_id_unique IF NOT EXISTS FOR (p:Playlist) REQUIRE p.id IS UNIQUE
CREATE CONSTRAINT track_id_unique IF NOT EXISTS FOR (track:Track) REQUIRE track.id IS UNIQUE
CREATE CONSTRAINT chart_id_unique IF NOT EXISTS FOR (chart:Chart) REQUIRE chart.id IS UNIQUESometimes this prompt would return statements for indexes and constraints, hense the split on the semi-colon.
Run the Import
With everything in place, it was time to execute ethe Cypher statements.
from os import getenv
from neo4j import GraphDatabase
driver = GraphDatabase.driver(
getenv("NEO4J_URI"),
auth=(
getenv("NEO4J_USERNAME"),
getenv("NEO4J_PASSWORD")
)
)
with driver.session() as session:
# truncate the db
session.run("MATCH (n) DETACH DELETE n")
# create constraints
for q in constraint_queries:
if q.strip() != "":
session.run(q)
# import the data
for q in import_cypher:
if q.strip() != "":
res = session.run(q, rows=rows).consume()
print(q)
print(res.counters)QA on the Data Set
This post wouldn’t be complete without some Question & Answering on the dataset using the GraphCypherQAChain.
from langchain.chains import GraphCypherQAChain
from langchain_community.graphs import Neo4jGraph
graph = Neo4jGraph(
url=getenv("NEO4J_URI"),
username=getenv("NEO4J_USERNAME"),
password=getenv("NEO4J_PASSWORD"),
enhanced_schema=True
)
qa = GraphCypherQAChain.from_llm(
llm,
graph=graph,
allow_dangerous_requests=True,
verbose=True
)Most Popular Artists
Who are the most popular artists in the database?
qa.invoke({"query": "Who are the most popular artists?"})> Entering new GraphCypherQAChain chain...
Generated Cypher:
cypher
MATCH (:Track)-[:PERFORMED_BY]->(a:Artist)
RETURN a.name, COUNT(*) AS popularity
ORDER BY popularity DESC
LIMIT 10
Full Context:
[{'a.name': 'Bad Bunny', 'popularity': 40}, {'a.name': 'Taylor Swift', 'popularity': 38}, {'a.name': 'The Weeknd', 'popularity': 36}, {'a.name': 'SZA', 'popularity': 23}, {'a.name': 'Kendrick Lamar', 'popularity': 23}, {'a.name': 'Feid', 'popularity': 21}, {'a.name': 'Drake', 'popularity': 19}, {'a.name': 'Harry Styles', 'popularity': 17}, {'a.name': 'Peso Pluma', 'popularity': 16}, {'a.name': '21 Savage', 'popularity': 14}]
> Finished chain.{
"query": "Who are the most popular artists?",
"result": "Bad Bunny, Taylor Swift, and The Weeknd are the most popular artists."
}The LLM seemed to judge popularity in terms of number of tracks an artist has been on rather than their overall number of streams.
Beats Per Minute
Which track has the highest BPM?
qa.invoke({"query": "Which track has the highest BPM?"})> Entering new GraphCypherQAChain chain...
Generated Cypher:
cypher
MATCH (t:Track)
RETURN t
ORDER BY t.bpm DESC
LIMIT 1
Full Context:
[{'t': {'id': 'seven-feat-latto-explicit-ver--2023'}}]
> Finished chain.{
"query": "Which track has the highest BPM?",
"result": "I don't know the answer."
}Improving the Cypher Generation Prompt
In this case, the Cypher looks fine and the correct result was included in the prompt but gpt-4o couldn’t interpret the answer. It looks like the CYPHER_GENERATION_PROMPT passed to the GraphCypherQAChain could do with additional instructions to make the column names more verbose.
Always use verbose column names in the Cypher statement using the label and property names. For example, use ‘person_name’ instead of ‘name’.
GraphCypherQAChain with Custom Prompt
CYPHER_GENERATION_TEMPLATE = """Task:Generate Cypher statement to query a graph database.
Instructions:
Use only the provided relationship types and properties in the schema.
Do not use any other relationship types or properties that are not provided.
Schema:
{schema}
Note: Do not include any explanations or apologies in your responses.
Do not respond to any questions that might ask anything else than for you to construct a Cypher statement.
Do not include any text except the generated Cypher statement.
Always use verbose column names in the Cypher statement using the label and property names. For example, use 'person_name' instead of 'name'.
Include data from the immediate network around the node in the result to provide extra context. For example, include the Movie release year, a list of actors and their roles, or the director of a movie.
When ordering by a property, add an `IS NOT NULL` check to ensure that only nodes with that property are returned.
Examples: Here are a few examples of generated Cypher statements for particular questions:
# How many people acted in Top Gun?
MATCH (m:Movie {{name:"Top Gun"}})
RETURN COUNT { (m)<-[:ACTED_IN]-() } AS numberOfActors
The question is:
{question}"""
CYPHER_GENERATION_PROMPT = PromptTemplate(
input_variables=["schema", "question"], template=CYPHER_GENERATION_TEMPLATE
)
qa = GraphCypherQAChain.from_llm(
llm,
graph=graph,
allow_dangerous_requests=True,
verbose=True,
cypher_prompt=CYPHER_GENERATION_PROMPT,
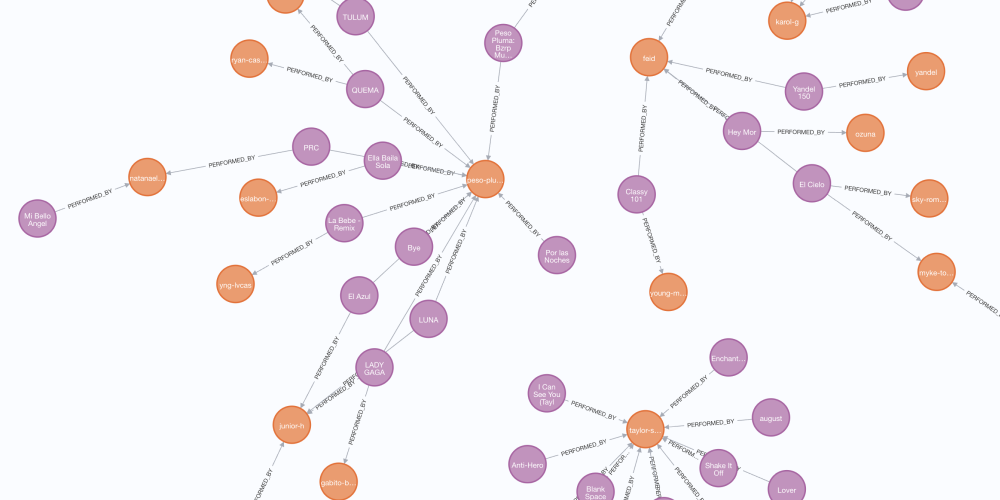
)Tracks performed by the most artists
Graphs excel at returning a count of the number of relationships by type and direction.
qa.invoke({"query": "Which tracks are performed by the most artists?"})> Entering new GraphCypherQAChain chain...
Generated Cypher:
cypher
MATCH (t:Track)
WITH t, COUNT { (t)-[:PERFORMED_BY]->(:Artist) } as artist_count
WHERE artist_count IS NOT NULL
RETURN t.id AS track_id, t.name AS track_name, artist_count
ORDER BY artist_count DESC
Full Context:
[{'track_id': 'los-del-espacio-2023', 'track_name': 'Los del Espacio', 'artist_count': 8}, {'track_id': 'se-le-ve-2021', 'track_name': 'Se Le Ve', 'artist_count': 8}, {'track_id': 'we-don-t-talk-about-bruno-2021', 'track_name': "We Don't Talk About Bruno", 'artist_count': 7}, {'track_id': 'cayï-ï-la-noche-feat-cruz-cafunï-ï-abhir-hathi-bejo-el-ima--2022', 'track_name': None, 'artist_count': 6}, {'track_id': 'jhoome-jo-pathaan-2022', 'track_name': 'Jhoome Jo Pathaan', 'artist_count': 6}, {'track_id': 'besharam-rang-from-pathaan--2022', 'track_name': None, 'artist_count': 6}, {'track_id': 'nobody-like-u-from-turning-red--2022', 'track_name': None, 'artist_count': 6}, {'track_id': 'ultra-solo-remix-2022', 'track_name': 'ULTRA SOLO REMIX', 'artist_count': 5}, {'track_id': 'angel-pt-1-feat-jimin-of-bts-jvke-muni-long--2023', 'track_name': None, 'artist_count': 5}, {'track_id': 'link-up-metro-boomin-don-toliver-wizkid-feat-beam-toian-spider-verse-remix-spider-man-across-the-spider-verse--2023', 'track_name': None, 'artist_count': 5}]
> Finished chain.{
"query": "Which tracks are performed by the most artists?",
"result": "The tracks \"Los del Espacio\" and \"Se Le Ve\" are performed by the most artists, with each track having 8 artists."
}Conclusion
The CSV analysis and modeling is the most time intensive part, it could take more than five minutes to generate.
The costs themselves were pretty cheap, in eight hours of experimentation I must have sent hundreds of request and I ended up spending a dollar or so.
There were a number of challenges to get to this point.
- The prompts took several iterations to get right. This problem could be overcome by fine-tuning the model or providing few-shot examples.
- JSON responses from gpt-4o can be inconsistent. I was recommended
json-repair, which was better than trying to get the LLM to validate its own JSON output.
I can see this approach working well in a LangGraph implementation where the operations are run in sequence, giving an LLM the ability to build and refine the model. As new models are released, they may also benefit from fine-tuning.
The next challenge for me is to convert the model into a format understood by the Data Importer in Neo4j Aura.
check out the Generative AI learning path on GraphAcademy.