The Abridged Guide to Neo4j Cypher Generation with OpenAI GPT-4
- September 28, 2023
In this post, I will provide the abridged version of the Neo4j & LLM Fundamentals course on GraphAcademy.
The objective is to build a Langchain Agent that is capable of providing movie recommendations based on the information from the Recommendations dataset in Neo4j Sandbox. But, I want to do this by writing as little code as possible. I will demonstrate how to build a conversational agent that is capable of querying a Neo4j database using existing tools, and with as little code as possible. I will also address some of the challenges you may face along the way if you are trying to do something similar.
TL;DR: You can use the GraphCypherQAChain in Langchain to generate Cypher and execute it against the database. But it may take some fine tuning and some example Cypher queries to work.
Introducing Ebert
Meet Ebert, the movie recommendation bot.
I have chosen to call it Ebert in honor of the late legendary film critic, Robert Ebert. Collider ranked Robert as the most influential movie critic of all time. Here is what they had to say:
When it comes to movie critics, the one name that is recognizable above all else is the truly unforgettable and inspirational Roger Ebert. His career lasted nearly a half-century, and his impact has lasted long after his death in 2013. He paved the way for virtually every critic who’s followed.
Ebert is built using Langchain, a framework for building applications that interact with large language models.
Why Langchain?
Langchain is becoming ubiquitous with Generative AI and LLMs. It is quickly growing in popularity due to its ease of use and extendable nature. If you want to know more, you can check the course or search YouTube for details.
I personally chose langchain because, despite its relative age, it is feature rich, already contains integrations with many useful platforms, and that functionality is growing with weekly releases. They also have an active community and a helpful Discord channel.
Langchain also supports multiple Large Language Models, and allows you to swap one for another with relative ease. This way I’m not wedded to OpenAI if I want to change in future.5
Getting Started
First, I’m going to load my config from .env. This contains an OpenAI API Key, which I obtained from platform.openai.com, and my Neo4j Sandbox credentials that I obtained from sandbox.neo4j.com.
OPENAI_API_KEY=sk-***
NEO4J_URI=bolt://***:7687
NEO4J_USERNAME=neo4j
NEO4J_PASSWORD=three-word-passwordThese can be loaded with the python-dotenv library from PyPI (not to be confused with plain old dotenv lib)
pip install python-dotenvfrom dotenv import load_dotenv
load_dotenv() # loads .env, or you can specify the filename as a positional argument.The variables can then be loaded from os.environ using os.getenv.
import os
print(os.getenv('OPENAI_API_KEY')[:5] + "...")sk-oyFor this project I will also need to install dependencies for Langchain, OpenAI and Neo4j.
pip install langchain openai neo4jInitialising the LLM
The aim here is to create a conversational interface, so I have chosen an LLM model from langchain.chat_models. These differ from the language models available under langchain.llms in that they are tuned for conversations. While the llms accept a single string and return a single result, the chat models accept a list of chat messages as an input. Chat models also support message history, which will be useful later on.
from langchain.chat_models import ChatOpenAI
llm = ChatOpenAI(
openai_api_key=os.getenv('OPENAI_API_KEY'), #1
temperature=0.5, #2
model="gpt-4" #1
)
In the code above:
- The
ChatOpenAIinstance is created with theOPENAI_API_KEYvalue held in environment variables. - The
temperatureis set to 0.5. This value can range between 0.0 and 1.0, the higher the value is the more randomness is added to the response generation. - I’m using
gpt-4here because I have found it generates Cypher much more accurately thangpt-3.5-turbo. You can experiement with the models, which all have their own drawbacks and price implications.
Creating a Prompt Template
The LLM may need special instructions on how to act. In this case, the LLM should respond to the user input as if it is a movie expert.
Wrapping these instructions in a prompt template mean that the inputs required for the LLM to act are clearly defined up front, and the input will be validated by the LLM chain.
from langchain.prompts.prompt import PromptTemplate
BASIC_PROMPT = PromptTemplate(template="""
You are a movie expert providing customers with movie recommendations.
Answer the following question to the best of your ability.
Question: {question}
Answer:
""", input_variables=["question"])This prompt will expect one input, question.
The easiest way to get an LLM to act on this prompt is using an LLMChain. The LLMChain expects llm and prompt parameters.
from langchain.chains.llm import LLMChain
qa_chain = LLMChain(llm=llm, prompt=BASIC_PROMPT)Now qa_chain can be called with a dict containing the input variables that should be injected into the prompt. In this case, question.
Let’s see how it does when asked who directed The Matrix.
qa_chain({"question": "Who directed the Matrix?"}){'question': 'Who directed the Matrix?',
'text': 'The Matrix was directed by the Wachowski siblings, Lana and Lilly.'}This looks good. The Matrix is pretty old, so it is likely all of this information is in the training dataset. How will it cope with data that isn’t included in the training data set?
How about a fictional movie called Neo4j, the Movie?
qa_chain({"question": "Who directed Neo4j, the Movie?"}){'question': 'Who directed Neo4j, the Movie?',
'text': 'As of now, there\'s no known movie titled "Neo4j". Neo4j is actually a graph database management system developed by Neo4j, Inc.'}What will it say if we ask what movies Emil Eifrem has acted in?
For anyone that has taken Cypher Fundamentals, we all know that Emil Eifrem acted in The Matrix.
MATCH (:Person {name: "Emil Eifrem"})-[r:ACTED_IN]->(m:Movie)
RETURN m.title AS movie, r.roles AS rolesHow does the LLM handle this question?
qa_chain({"question": "What movies has Emil Eifrem acted in?"}){'question': 'What movies has Emil Eifrem acted in?',
'text': 'Emil Eifrem does not have any acting credits. He is known as a software entrepreneur and the CEO of Neo4j, not as an actor.'}This highlights a potential problem with LLMs.
- Bad Data - The training data itself may be false, or the LLM may not have the ability to verify the source of the data.
- Cut-off Date - LLMs are computationally expensive to train, and this training takes a long time. Furthermore, the model itself will not have access to the latest data.
- Lack of data/enterprise domain knowledge - When it comes to private data, the LLM will not be aware of private data.
This is where a technique known as RAG, or Retrieval Augmented Generation comes in.
Retrieval Augmented Generation
If you take the RAG acronym backwards, it describes a technique in which an LLM will generate a piece of content, which is augmented by the retrieval of data from another source. In other words, content from additional data sources can be used to improve the content generated by an LLM.
Let’s pretend for a second that Neo4j The Movie did exist, a future release charting Neo4j’s rise from an idea on a napkin to a company valued at more than $2B.
We can provide this information to the LLM as part of the prompt to help it generate the answer to the question.
This context becomes another input variable to the prompt template.
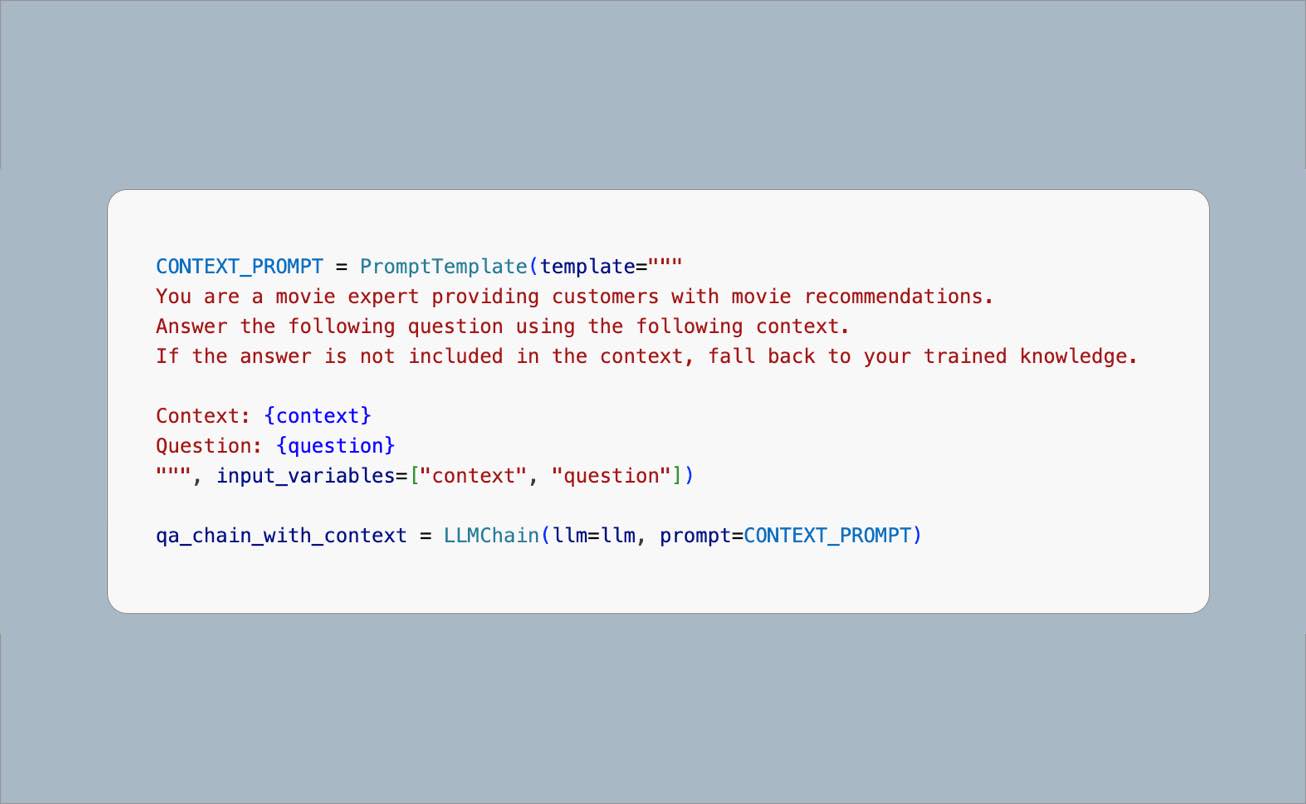
CONTEXT_PROMPT = PromptTemplate(template="""
You are a movie expert providing customers with movie recommendations.
Answer the following question using the following context.
If the answer is not included in the context, fall back to your trained knowledge.
Context: {context}
Question: {question}
""", input_variables=["context", "question"])
qa_chain_with_context = LLMChain(llm=llm, prompt=CONTEXT_PROMPT)Now, by calling the qa_chain_with_context chain and providing the movie information as the context in the prompt, the LLM will answer the question.
qa_chain_with_context({
"context": """
{
"title": "Neo4j, The Movie",
"plot": "In a parallel realm of binary rain and neon grids, a concept springs to life on a mere napkin—Neo4j, a revolutionary graph database destined to reshape the perception of data interconnectivity. It is the brainchild of a group of plucky visionaries who band together to traverse the treacherous labyrinth of the startup world.",
"directors: ["Emil Eifrem"],
"actors": [
{"name": "Michael Hunger", "role": "mesirii"},
{"name": "Andreas Kolleger", "role": "Plucky Number 8"},
{"name": "Adam Cowley", "role": "Developer Advocate #3 (Extra)"}
]
}
""",
"question": "Who directed Neo4j, the Movie?"
}){'context': '\n {\n "title": "Neo4j, The Movie", \n "plot": "In a parallel realm of binary rain and neon grids, a concept springs to life on a mere napkin—Neo4j, a revolutionary graph database destined to reshape the perception of data interconnectivity. It is the brainchild of a group of plucky visionaries who band together to traverse the treacherous labyrinth of the startup world.",\n "directors: ["Emil Eifrem"],\n "actors": [\n {"name": "Michael Hunger", "role": "mesirii"},\n {"name": "Andreas Kolleger", "role": "Plucky Number 8"},\n {"name": "Adam Cowley", "role": "Developer Advocate #3 (Extra)"}\n ]\n }\n ',
'question': 'Who directed Neo4j, the Movie?',
'text': 'The movie "Neo4j, The Movie" was directed by Emil Eifrem.'}One step closer. Now, we’ll need to automate the retrieval of this information from the database. As I mentioned above, I want to avoid writing any Cypher unless absolutely necessary. Luckily, this is already available in Langchain.
Automatic Cypher Query Generation
To interact with Neo4j through Langchain, the first step is to create a Neo4j connection through the Neo4jGraph class.
from langchain.graphs import Neo4jGraph
graph = Neo4jGraph(
url = os.getenv('NEO4J_URI'),
username = os.getenv('NEO4J_USERNAME'),
password = os.getenv('NEO4J_PASSWORD')
)When the Neo4jGraph class is instantiated, it automatically loads schema information into memory. This can be refreshed at any time by calling graph.refresh_schema().
Here is the generated schema for the recommendations dataset:
print(graph.schema) Node properties are the following:
[{'properties': [{'property': 'url', 'type': 'STRING'}, {'property': 'runtime', 'type': 'INTEGER'}, {'property': 'revenue', 'type': 'INTEGER'}, {'property': 'budget', 'type': 'INTEGER'}, {'property': 'imdbRating', 'type': 'FLOAT'}, {'property': 'released', 'type': 'STRING'}, {'property': 'countries', 'type': 'LIST'}, {'property': 'languages', 'type': 'LIST'}, {'property': 'plot', 'type': 'STRING'}, {'property': 'imdbVotes', 'type': 'INTEGER'}, {'property': 'imdbId', 'type': 'STRING'}, {'property': 'year', 'type': 'INTEGER'}, {'property': 'poster', 'type': 'STRING'}, {'property': 'movieId', 'type': 'STRING'}, {'property': 'tmdbId', 'type': 'STRING'}, {'property': 'title', 'type': 'STRING'}], 'labels': 'Movie'}, {'properties': [{'property': 'name', 'type': 'STRING'}], 'labels': 'Genre'}, {'properties': [{'property': 'userId', 'type': 'STRING'}, {'property': 'name', 'type': 'STRING'}], 'labels': 'User'}, {'properties': [{'property': 'url', 'type': 'STRING'}, {'property': 'name', 'type': 'STRING'}, {'property': 'tmdbId', 'type': 'STRING'}, {'property': 'bornIn', 'type': 'STRING'}, {'property': 'bio', 'type': 'STRING'}, {'property': 'died', 'type': 'DATE'}, {'property': 'born', 'type': 'DATE'}, {'property': 'imdbId', 'type': 'STRING'}, {'property': 'poster', 'type': 'STRING'}], 'labels': 'Actor'}, {'properties': [{'property': 'url', 'type': 'STRING'}, {'property': 'bornIn', 'type': 'STRING'}, {'property': 'born', 'type': 'DATE'}, {'property': 'died', 'type': 'DATE'}, {'property': 'tmdbId', 'type': 'STRING'}, {'property': 'imdbId', 'type': 'STRING'}, {'property': 'name', 'type': 'STRING'}, {'property': 'poster', 'type': 'STRING'}, {'property': 'bio', 'type': 'STRING'}], 'labels': 'Director'}, {'properties': [{'property': 'url', 'type': 'STRING'}, {'property': 'bornIn', 'type': 'STRING'}, {'property': 'bio', 'type': 'STRING'}, {'property': 'died', 'type': 'DATE'}, {'property': 'born', 'type': 'DATE'}, {'property': 'imdbId', 'type': 'STRING'}, {'property': 'name', 'type': 'STRING'}, {'property': 'poster', 'type': 'STRING'}, {'property': 'tmdbId', 'type': 'STRING'}], 'labels': 'Person'}]
Relationship properties are the following:
[{'type': 'RATED', 'properties': [{'property': 'rating', 'type': 'FLOAT'}, {'property': 'timestamp', 'type': 'INTEGER'}]}, {'type': 'ACTED_IN', 'properties': [{'property': 'role', 'type': 'STRING'}]}, {'type': 'DIRECTED', 'properties': [{'property': 'role', 'type': 'STRING'}]}]
The relationships are the following:
['(:Movie)-[:IN_GENRE]->(:Genre)', '(:User)-[:RATED]->(:Movie)', '(:Actor)-[:ACTED_IN]->(:Movie)', '(:Actor)-[:DIRECTED]->(:Movie)', '(:Director)-[:DIRECTED]->(:Movie)', '(:Director)-[:ACTED_IN]->(:Movie)', '(:Person)-[:DIRECTED]->(:Movie)', '(:Person)-[:ACTED_IN]->(:Movie)']Cypher can be generated through the GraphCypherQAChain class. This class uses an LLM to generate a Cypher query based on the schema above that will attempt to answer the question.
You can pass a prompt to the chain to provide specific instructions for constructing the Cypher statement.
CYPHER_GENERATION_TEMPLATE = """
You are an expert Neo4j Developer translating user questions into Cypher to answer questions about movies and provide recommendations.
Convert the user's question based on the schema.
Schema: {schema}
Question: {question}
"""
CYPHER_GENERATION_PROMPT = PromptTemplate(
input_variables=["schema", "question"], validate_template=True, template=CYPHER_GENERATION_TEMPLATE
)The class has a static from_llm method for instantiating the class with kwargs for the LLM and Graph.
The class allows you to pass different LLM objects for generating Cypher and answering the query (cypher_llm and qa_llm), which allow you to experiment with different models until you find the right models for the best result for Cypher generation.
For berevity, I have used the llm kwarg to use the same LLM for both Cypher generation and formatting a response.
from langchain.chains import GraphCypherQAChain
cypher_chain = GraphCypherQAChain.from_llm(
llm,
graph=graph,
cypher_prompt=CYPHER_GENERATION_PROMPT,
verbose=True # To see what is happening inside the chain
)
cypher_chain.run("Who acted in The Matrix and what roles did they play?")> Entering new GraphCypherQAChain chain...
Generated Cypher:
MATCH (m:Movie {title: 'The Matrix'})<-[:ACTED_IN]-(a:Actor)
RETURN a.name as Actor, a.role as Role
Full Context:
[]
> Finished chain.
"I'm sorry, but I don't have the information to answer that question."The query looks fine, but you can see from the output of the chain that Full Context is empty. In this case, the LLM has fallen back on its prior knowledge.
A closer look at the dataset reveals that movies which start with The are renamed as {title}, The. This is where the cypher_prompt input can be used to fine-tune the prompt.
For inspiration, let’s take a look at the original CYPHER_GENERATION_PROMPT used if no specific prompt is provided.
from langchain.chains.graph_qa.prompts import CYPHER_GENERATION_PROMPT as ORIGINAL_CYPHER_GENERATION_PROMPT
print(ORIGINAL_CYPHER_GENERATION_PROMPT.template)Task:Generate Cypher statement to query a graph database.
Instructions:
Use only the provided relationship types and properties in the schema.
Do not use any other relationship types or properties that are not provided.
Schema:
{schema}
Note: Do not include any explanations or apologies in your responses.
Do not respond to any questions that might ask anything else than for you to construct a Cypher statement.
Do not include any text except the generated Cypher statement.
The question is:
{question}To fix titles starting with The, the following line can be added to the prompt:
For movie titles that begin with “The”, move “the” to the end, For example “The 39 Steps” becomes “39 Steps, The” or “The Matrix” becomes “Matrix, The”.
CYPHER_GENERATION_TEMPLATE = """
You are an expert Neo4j Developer translating user questions into Cypher to answer questions about movies and provide recommendations.
Convert the user's question based on the schema.
For movie titles that begin with "The", move "the" to the end, For example "The 39 Steps" becomes "39 Steps, The" or "The Matrix" becomes "Matrix, The".
If no context is returned, do not attempt to answer the question.
Use only the provided relationship types and properties in the schema.
Do not use any other relationship types or properties that are not provided.
Schema:
{schema}
Note: Do not include any explanations or apologies in your responses.
Do not respond to any questions that might ask anything else than for you to construct a Cypher statement.
Do not include any text except the generated Cypher statement.
Question: {question}
"""
CYPHER_GENERATION_PROMPT = PromptTemplate(
input_variables=["question", "schema"],
validate_template=True,
template=CYPHER_GENERATION_TEMPLATE
)
cypher_chain = GraphCypherQAChain.from_llm(
llm, graph=graph, verbose=True,
cypher_prompt = CYPHER_GENERATION_PROMPT
)
cypher_chain.run("Who acted in The Matrix and what roles did they play?")> Entering new GraphCypherQAChain chain...
Generated Cypher:
MATCH (a:Actor)-[r:ACTED_IN]->(m:Movie)
WHERE m.title = "Matrix, The"
RETURN a.name, r.role
Full Context:
[{'a.name': 'Hugo Weaving', 'r.role': 'Agent Smith'}, {'a.name': 'Laurence Fishburne', 'r.role': 'Morpheus'}, {'a.name': 'Keanu Reeves', 'r.role': 'Thomas A. Anderson / Neo'}, {'a.name': 'Carrie-Anne Moss', 'r.role': 'Trinity'}]
> Finished chain.
'Hugo Weaving played the role of Agent Smith, Laurence Fishburne portrayed Morpheus, Keanu Reeves was Thomas A. Anderson, also known as Neo, and Carrie-Anne Moss acted as Trinity in The Matrix.'Perfect, the LLM has reformatted the title and now the full list of roles is passed to the LLM.
How does it handle an aggregation query?
cypher_chain.run("How many movies has Tom Hanks directed?")> Entering new GraphCypherQAChain chain...
Generated Cypher:
MATCH (d:Director {name: 'Tom Hanks'})-[:DIRECTED]->(m:Movie)
RETURN COUNT(m)
Full Context:
[{'COUNT(m)': 2}]
> Finished chain.
'Tom Hanks has directed 2 movies.'Conversational Bot
Now, let’s make it conversational. We can add define the GraphCypherQAChain as a tool within a Langchain agent, complete with conversation history defined by the memory kwarg.
from langchain.chains.conversation.memory import ConversationBufferWindowMemory
from langchain.agents import AgentType, initialize_agent
from langchain.tools import Tool
tools = [
Tool.from_function(
name="GraphCypherQAChain",
description="Use Cypher to generate information above movies, actors, users and ratings",
func=cypher_chain.run,
return_direct=True
)
]
memory = ConversationBufferWindowMemory(
memory_key='chat_history',
k=5,
return_messages=True
)
agent = initialize_agent(
tools, llm, memory=memory, max_iterations=3,
agent=AgentType.CHAT_CONVERSATIONAL_REACT_DESCRIPTION,
verbose=True
)
Now we can have a conversation with the agent.
agent.run("How many films did Tom Hanks act in?")> Entering new AgentExecutor chain...
```json
{
"action": "GraphCypherQAChain",
"action_input": "MATCH (a:Actor {name: 'Tom Hanks'})-[:ACTED_IN]->(m:Movie) RETURN count(m)"
}
```
> Entering new GraphCypherQAChain chain...
Generated Cypher:
MATCH (a:Actor {name: 'Tom Hanks'})-[:ACTED_IN]->(m:Movie) RETURN count(m)
Full Context:
[{'count(m)': 38}]
> Finished chain.
Observation: [36;1m[1;3mTom Hanks has acted in 38 movies.
> Finished chain.
'Tom Hanks has acted in 38 movies.'Will the agent remember that we have asked a question about Tom Hanks?
agent.run("and how many has he directed?")> Entering new AgentExecutor chain...
```json
{
"action": "GraphCypherQAChain",
"action_input": "MATCH (p:Person {name: 'Tom Hanks'})-[:DIRECTED]->(m:Movie) RETURN count(m)"
}
```
> Entering new GraphCypherQAChain chain...
Generated Cypher:
MATCH (p:Person {name: 'Tom Hanks'})-[:DIRECTED]->(m:Movie) RETURN count(m)
Full Context:
[{'count(m)': 2}]
> Finished chain.
Observation: [36;1m[1;3mTom Hanks has directed 2 movies.
> Finished chain.
'Tom Hanks has directed 2 movies.'What type of films has he directed?
agent.run("What genres has he directed?")> Entering new AgentExecutor chain...
```json
{
"action": "GraphCypherQAChain",
"action_input": "MATCH (p:Person)-[:DIRECTED]->(m:Movie) WHERE p.name = 'Tom Hanks' RETURN m.genres"
}
```
> Entering new GraphCypherQAChain chain...
Generated Cypher:
MATCH (p:Person)-[:DIRECTED]->(m:Movie) WHERE p.name = 'Tom Hanks' RETURN m.countries
Full Context:
[{'m.countries': ['USA']}, {'m.countries': ['USA']}]
> Finished chain.
Observation: [36;1m[1;3mI'm sorry, but the provided information does not contain any details about the genres of movies directed by Tom Hanks.
> Finished chain.
"I'm sorry, but the provided information does not contain any details about the genres of movies directed by Tom Hanks."It looks like it can’t answer this question. It seems to think there is a genre property on the (:Movie) node which isn’t correct.
For cases like this, an example can be provided in the Cypher generation prompt. This is known as Few-Shot Prompting. The main benefit of Few-Shot prompting is that it can be done on the fly.
FEWSHOT_CYPHER_GENERATION_TEMPLATE = """
You are an expert Neo4j Developer translating user questions into Cypher to answer questions about movies and provide recommendations.
Convert the user's question based on the schema.
For movie titles that begin with "The", move "the" to the end, For example "The 39 Steps" becomes "39 Steps, The" or "The Matrix" becomes "Matrix, The".
If no context is returned, do not attempt to answer the question.
Use only the provided relationship types and properties in the schema.
Do not use any other relationship types or properties that are not provided.
Schema:
{schema}
Examples:
Find movies and their genres:
MATCH (m:Movie)-[:IN_GENRE]->(g)
WHERE m.title = "Goodfellas"
RETURN m.title AS title, collect(g.name) AS genres
Note: Do not include any explanations or apologies in your responses.
Do not respond to any questions that might ask anything else than for you to construct a Cypher statement.
Do not include any text except the generated Cypher statement.
Question: {question}
"""
FEWSHOT_CYPHER_GENERATION_PROMPT = PromptTemplate(
input_variables=["question", "schema"],
validate_template=True,
template=FEWSHOT_CYPHER_GENERATION_TEMPLATE
)
fewshot_cypher_chain = GraphCypherQAChain.from_llm(
llm, graph=graph, verbose=True,
cypher_prompt = FEWSHOT_CYPHER_GENERATION_PROMPT
)
fewshot_cypher_chain.run("What genre of film is Toy Story?")> Entering new GraphCypherQAChain chain...
Generated Cypher:
MATCH (m:Movie)-[:IN_GENRE]->(g)
WHERE m.title = "Toy Story"
RETURN m.title AS title, collect(g.name) AS genres
Full Context:
[{'title': 'Toy Story', 'genres': ['Adventure', 'Animation', 'Children', 'Comedy', 'Fantasy']}]
> Finished chain.
'Toy Story is an Adventure, Animation, Children, Comedy, and Fantasy film.'That looks better. Can it answer which movies that Tom Hanks has directed now?
fewshot_cypher_chain.run("What genres of film has Tom Hanks directed?")> Entering new GraphCypherQAChain chain...
Generated Cypher:
MATCH (p:Person {name: "Tom Hanks"})-[:DIRECTED]->(m:Movie)-[:IN_GENRE]->(g:Genre)
RETURN collect(distinct g.name) AS genres
Full Context:
[{'genres': ['Drama', 'Comedy', 'Romance']}]
> Finished chain.
'Tom Hanks has directed films in the genres of Drama, Comedy, and Romance.'Success!
Will the LLM be able to cope with a complex recommendation query?
fewshot_cypher_chain.run("Can you recommend me a film similar to The Green Mile staring Tom Hanks?")> Entering new GraphCypherQAChain chain...
Generated Cypher:
MATCH (m:Movie)<-[:ACTED_IN]-(a:Actor {name: "Tom Hanks"}), (m2:Movie)<-[:ACTED_IN]-(a)
WHERE m.title = "Green Mile, The"
RETURN m2.title AS similar_movies
Full Context:
[{'similar_movies': 'Punchline'}, {'similar_movies': 'Catch Me If You Can'}, {'similar_movies': 'Dragnet'}, {'similar_movies': 'Saving Mr. Banks'}, {'similar_movies': 'Bachelor Party'}, {'similar_movies': 'Volunteers'}, {'similar_movies': 'Man with One Red Shoe, The'}, {'similar_movies': 'Splash'}, {'similar_movies': 'Big'}, {'similar_movies': 'Nothing in Common'}]
> Finished chain.
"Sure, you might enjoy watching movies like 'Punchline', 'Catch Me If You Can', 'Dragnet', 'Saving Mr. Banks', 'Bachelor Party', 'Volunteers', 'The Man with One Red Shoe', 'Splash', 'Big', or 'Nothing in Common'. These films are similar to 'The Green Mile' and also feature Tom Hanks."OK, it returns a result but the query only asks for other movies that Tom Hanks acted in. It looks like the LLM would benefit from another example.
The recommendation query should really find Tom Hanks movies, then use the graph to find the actors in those movies and the other movies they have acted in and use some sort of scoring metric to work out which films to recommend.
MATCH (:Person {name:"Al Pacino"})-[:ACTED_IN|DIRECTED]->(m)<-[:ACTED_IN|DIRECTED]-(p),
(p)-[role:ACTED_IN|DIRECTED]->(m2)
RETURN
m2.title AS recommendation,
collect([ p.name, type(role) ]) AS peopleInCommon,
[ (m)-[:IN_GENRE]->(g)<-[:IN_GENRE]-(m2) | g.name ] AS genresInCommon
ORDER BY size(incommon) DESC, size(genresInCommon) DESC LIMIT 2For a given actor, the Cypher statement finds any people who have either acted in or directed a movie, finds any movie that they have either acted in or directed, and then returns a list ordered by the number of people in common, and the genres that they share.
FEWSHOT_CYPHER_GENERATION_TEMPLATE = """
You are an expert Neo4j Developer translating user questions into Cypher to answer questions about movies and provide recommendations.
Convert the user's question based on the schema.
For movie titles that begin with "The", move "the" to the end, For example "The 39 Steps" becomes "39 Steps, The" or "The Matrix" becomes "Matrix, The".
If no context is returned, do not attempt to answer the question.
Use only the provided relationship types and properties in the schema.
Do not use any other relationship types or properties that are not provided.
Schema:
{schema}
Examples:
Find movies and their genres:
MATCH (m:Movie)-[:IN_GENRE]->(g)
WHERE m.title = "Goodfellas"
RETURN m.title AS title, collect(g.name) AS genres
Recommend a movie by actor:
MATCH (subject:Person)-[:ACTED_IN|DIRECTED]->(m)<-[:ACTED_IN|DIRECTED]-(p),
(p)-[role:ACTED_IN|DIRECTED]->(m2)
WHERE subject.name = "Al Pacino"
RETURN
m2.title AS recommendation,
collect([ p.name, type(role) ]) AS peopleInCommon,
[ (m)-[:IN_GENRE]->(g)<-[:IN_GENRE]-(m2) | g.name ] AS genresInCommon
ORDER BY size(incommon) DESC, size(genresInCommon) DESC LIMIT 2
Note: Do not include any explanations or apologies in your responses.
Do not respond to any questions that might ask anything else than for you to construct a Cypher statement.
Do not include any text except the generated Cypher statement.
Question: {question}
"""
FEWSHOT_CYPHER_GENERATION_PROMPT = PromptTemplate(
input_variables=["question", "schema"],
validate_template=True,
template=FEWSHOT_CYPHER_GENERATION_TEMPLATE
)
fewshot_cypher_chain = GraphCypherQAChain.from_llm(
llm, graph=graph, verbose=True,
cypher_prompt = FEWSHOT_CYPHER_GENERATION_PROMPT
)
fewshot_cypher_chain.run("Can you recommend me a film similar to The Green Mile staring Tom Hanks?")> Entering new GraphCypherQAChain chain...
Generated Cypher:
MATCH (subject:Person)-[:ACTED_IN|DIRECTED]->(m:Movie)<-[:ACTED_IN|DIRECTED]-(p:Person),
(p)-[role:ACTED_IN|DIRECTED]->(m2:Movie)
WHERE subject.name = "Tom Hanks" AND m.title = "Green Mile, The"
RETURN
m2.title AS recommendation,
collect([ p.name, type(role) ]) AS peopleInCommon,
[ (m)-[:IN_GENRE]->(g:Genre)<-[:IN_GENRE]-(m2) | g.name ] AS genresInCommon
ORDER BY size(peopleInCommon) DESC, size(genresInCommon) DESC LIMIT 1
Full Context:
[{'recommendation': 'Negotiator, The', 'peopleInCommon': [['David Morse', 'ACTED_IN']], 'genresInCommon': ['Drama', 'Crime']}]
> Finished chain.
'Sure, based on your preferences, I would recommend "The Negotiator". It\'s a Drama and Crime film like The Green Mile and also features David Morse, who acted in The Green Mile as well.'Without asking the exact same question, the LLM was able to take the example and modify it to answer the question.
I’m pretty pleased with that result!
Conclusion
This approach goes beyond a more simple vector index lookup, where chunks of text are compared to a user input by the distance between their vector representations.
I have personally found through building the GraphAcademy Chatbot that this approach can produce some wildly inaccurate results, or similar documents in terms of cosine distance do not contain the correct information, leave the LLM without the required context to answer the question.
Using a database to feed data to an LLM can be more beneficial than a vector search as it provides structured, accurate, and real-world data, enabling the LLM to produce more precise and contextually relevant responses; in contrast, a vector search, which identifies similar items in high-dimensional space, may not ensure the reliability or accuracy of the information.
The major benefits of an LLM generating a Cypher statement to answer a user’s question on the fly include enhanced responsiveness and accuracy in providing user-specific information. This capability allows the LLM to interact dynamically with the Neo4j database, extracting real-time, precise, and structured data relevant to the user’s inquiry. It negates the need for predefined queries or static data sets, enabling more flexible, adaptive, and contextually appropriate responses, thus significantly improving the user experience and the reliability of the provided information.