Calculating TF-IDF scores in Neo4j with Cypher
- August 30, 2021
When extracting information from documents using NLP, attempting to separate important terms from noise can be tricky. By Calculating a TF-IDF (Term Frequency-Inverse Document Frequency) score, you can elevate important terms in a document compared to the document set overall. This is a nice addition to the Bag of Words approach to Natural Language Processing because it dampens the score of commonly mentioned terms that do not contain as much informational content.
TL;DR: The full query is at the bottom of this post.
TF-IDF: The Theory
Say we’re analysing a set of emails. Terms like “Dear IT Support” and “kind regards” are commonly used and will appear often in the corpus. These terms are noise compared to the important terms that we would like to extract, like place names or products.
The Term Frequency (TF) scores the frequency of a word in a given document. This is calculated by taking the number of times a term is mentioned in the document and dividing it by the total number of terms mentioned in the document.
n/N # n = Mentions of term in document, N = Total terms in documentThe Inverse Document Frequency (IDF) is calculated by taking the total number of documents, the number of documents that a given term is mentioned in and dividing before adding to a logarithmic scale.
1 + log(N/n) # N = Total number of documents, n = Documents that mention the termThere are many packages around that will calculate TF-IDF scores, but as this is a relatively simple calculation we can do this using only a Cypher statement.
Data Model
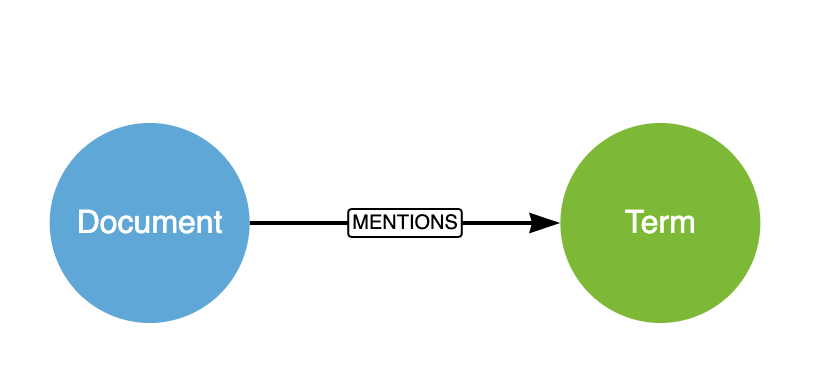
The simplest way to analyse this in Neo4j would be to extract words and/or ngrams from a body of text into a :Document node with a :MENTIONS relationship to one or more :Term nodes.
Approach
First, we’ll need the total number of documents. Then, choose a term and document to calculate the score for.
MATCH (:Document) WITH count(*) AS totalDocuments
MATCH (t:Term {name: $term})
MATCH (d:Document {id: $id})Next, we’ll need to gather some statistical information on the term and the document:
WITH d, t,
totalDocuments,
size((d)-[:MENTIONS]->(t)) AS occurrencesInDocument,
size((d)-[:MENTIONS]->()) AS termsInDocument,
size(()-[:MENTIONS]->(t)) AS documentsWithTermThen, calculate the tf, and the idf scores
WITH d, t,
totalDocuments,
1.0 * occurrencesInDocument / termsInDocument AS tf,
log10( totalDocuments / documentsWithTerm ) AS idfFinally, multiply the TF by the IDF to get a score. This will give us the ID of the document node, the name property of the term and a tf-idf score. This value could be stored on the :MENTIONS relationship and then used to return relevant scores at query time. You may also want to remove scores under a particular threshold or only keep references to the top X values.
RETURN d.id, t.name, tf * idf as tfIdfFull Query
// Total number of documents
MATCH (:Document) WITH count(*) AS totalDocuments
// Pick a Term and a Document
MATCH (t:Term {name: $term})
MATCH (d:Document {id: $id})
// Get Statistics on Document and Term
WITH d, t,
totalDocuments,
size((d)-[:MENTIONS]->(t)) AS occurrencesInDocument,
size((d)-[:MENTIONS]->()) AS termsInDocument,
size(()-[:MENTIONS]->(t)) AS documentsWithTerm
// Calculate TF and IDF
WITH d, t,
totalDocuments,
1.0 * occurrencesInDocument / termsInDocument AS tf,
log10( totalDocuments / documentsWithTerm ) AS idf
// Combine together to return a result
RETURN d.id, t.name, tf * idf as tfIdf